
今回は、AI を使った文章自動生成の方法の概要をご紹介します。参考にした教材はUdemyの動画教材である「自然言語処理とチャットボット:AIによる文章生成と会話エンジン開発」です。

(画像出典)自然言語処理とチャットボット: AIによる文章生成と会話エンジン開発 | Udemy
サイバーウェーブでは「スキルアップ支援制度」として、社員が自己研鑽のための勉強代を補助する制度があります。この制度を使って「自然言語処理とチャットボット:AIによる文章生成と会話エンジン開発」を勉強しました。
なんとこの教材の説明書には「夏目漱石や宮沢賢治、江戸川乱歩の文体を模倣した、テキストの自動生成を行います」とあります。
つまりこの教材をしっかり学べば、素敵な文章を書く諸先生方の文章をAIに作ってもらえるかもしれないということ……夢が広がります。
教材の中では学習モデルとしてRNN(回帰型ニューラルネットワーク、Recurrent neural network)やLSTM(長・短期記憶、Long Short Term Memory)などが紹介されています。今回はRNNと呼ばれる手法を使って文章を作りました。プログラミング言語としてはPython を使っています。
目次
- 文章生成の全体像
- 学習するデータの前処理
- 文章データのベクトル化
- RNNの構築
- 学習の結果
- 感想
1 文章生成の全体像
今回は、機械学習の一種である教師あり学習を使いました。
教師あり学習とは、機械にデータの予測を行わせ、出力されたデータと正解データとの誤差をチェックさせて学習を進める方法です。誤差が小さくなるようなデータの作り方を機械が学ぶことで、予測値の精度が上がっていきます。
教師あり学習では、正解のデータを用意する必要があります。今回の文章生成では、学習用のテキストデータを時系列データとして扱いました。時系列データとは、時間の変化によって値が変わるデータのことです。株価などは身近な時系列データの一例です。文章を単語データの並びと捉えれば、時系列データとして見ることができます。
テキストデータを数値データとして扱えるようにするため、one-hot表現を使ってデータをベクトル化します。one-hot表現とは [ [1 0 0], [0 1 0] ] のように、複数の次元をもつベクトルのうち1つだけを「1」に、残りを「0」に符号化したベクトルを指します(詳しくは後述します)。ベクトル化したデータをRNNに入力すると、機械学習が行えます。
以上の工程を、教材の手順に沿って進めてみます。
2 学習するデータの前処理
学習用のデータとして文章データが必要です。今回は、青空文庫からダウンロードした
江戸川乱歩『怪人二十面相』を使いました。
しかし、ダウンロードした文章には漢字のルビや空白などの不要な情報も含まれており、そのまま学習に使うことはできません。データの前処理を行って、使わない情報を取り除く必要があります。
【元の文章】

《》などの記号を取り除くと、以下の画像のようになります。段落始めの空白や、漢字に振られたルビがなくなりました。
【データ処理後の文章】

3 文章データのベクトル化
次に、前処理した文章データに対して、文章を単語に分割する処理である形態素解析を行います。例えば、形態素解析を行うと
私は学校へ行く
という文章を
私 | は | 学校 | へ | 行く
のように、単語ごとに分割することができます。
分割した単語リストをone-hot表現によりベクトル化することで、学習用のデータを作ります。
one-hot表現とは、単語を1と0から構成されるベクトルで表現する方法です。例えば「猫」という単語を
[1,0]
「犬」という単語を
[0,1]
などのようにベクトル化することで、単語を区別しています。
単語をone-hot表現にすることで、学習に使う入力データと正解のデータを数値化して扱えるようになりました。
4 RNNの構築
RNNは時系列データの扱いに適した学習モデルであり、入力層、中間層、出力層で形成されています。入力層のデータは中間層で処理され、新しいデータとして出力されます。この出力されたデータを次のエポック(学習)の中間層に、入力データと一緒に入力します。
これを繰り返すことで学習が進められ、予測値と正解値との誤差が縮まっていきます。
RNNを構築するために、エポック数(学習の回数)や中間層のニューロン(入力された情報を変換して出力する仕組み)の数などを指定しておきます。
また、各エポックが終了するごとに文章を生成してもらうコードも書いておきます。これで、学習の回数を重ねることで生成される文章がどう変化していくかがわかります。
5 学習の結果
テキストデータ前処理、単語のベクトル化、RNNの構築をすることで、機械学習のための準備が整いました。
ここで、AIに文章を生成してもらいます。学習によって文章がどうなるかを比較するために、学習1回目の文章と50回目の文章を載せました。
【学習1回目】
そのころ、東京中の町のです。
「のは、、のは、は、、のとは、そのは、は、は、は、は、は、とのです。
「そのは、いのです。
「は、、のとは、、のは、は、は、なのです。
「と、、のののは、、ののには、、とは、いのです。
「のは、そのです。
「は、、のとは、、うに、、のです。
「と、、こに、、れのは、ののには、、ののとを、、とのは、なんに、って、ました。
「のと、、このは、は、は、のののです。
「いは、そのです。
「のは、、のは、ないは、そのは、っていました。
「は、、のとは、そのです。
「と、、そのは、は、いのは、、のとに、、うに、、のには、いのです。
【学習50回目】
そのころ、東京中の町という町といかりまるでして、このほどの手紙を、ここにしても、それをさっていたんですが。」
左門老人は、この人々の用意になっても、これらないとばかり、ひとりのことがおきました。
「お金がました。ぼくはその男をおといているんだぜ。」
観音さまは、あげたを席上に来てのでめた。
「では、まっかく出発しました。あありました。小林君は、するは明智さんのかったのです。
「おや、きみは、じつにおかぎていました。
「で、何もおさするのでした。
「だが、そうなんばかなっているのです。
「ハハハ……、ごちゃありませんか。」
明智は、この二十面相のことでしょう。いけなります。それからいつまで、その手には、何ものここにをついて、そういきました。
「では、きょう、日下部のというのでしょうか。」
「そうです。」
「それでも、あってもしかしたからね。」
「さす、どこい美術品がでいっているんだ。」
「ハハハ……、ご老人、そ
学習回数を重ねることで文章らしくなることがわかります。
以下の画像は、縦軸に予測値と正解値との誤差をとったグラフです。数値で見ても、学習を繰り返すことで誤差が縮まっていくことがわかります。
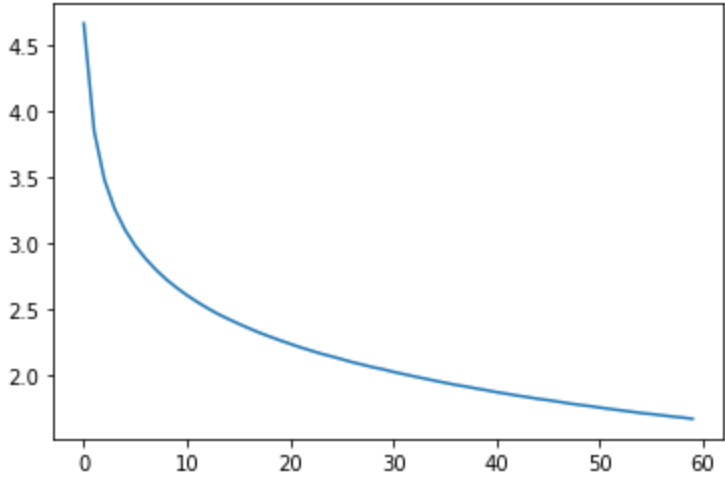
6 感想
今回はRNNを使って文章の自動生成を行いました。文章の印象や語彙は『怪人二十面相』に似ていますが、不自然な文脈になってしまっています。AI に江戸川乱歩のような文章を作ってほしかったのですが、面白い小説にするためには工夫が必要そうです。
文章には起承転結や序破急などの構成があります。単語を並べるだけではなく、全体の構成も考慮して文章生成ができると小説らしくなるかもしれません。
【参考資料】
Udemy動画教材 我妻幸長「自然言語処理とチャットボット:AIによる文章生成と会話エンジン開発」
神嶌敏弘編『深層学習』
Tariq Rashid著、新納浩幸監訳『ニューラルネットワーク自作入門』
サイバーウェーブでは一緒に働く仲間を募集しています
サイバーウェーブでは一緒に働く仲間を募集しています。当社は創業20年を機に「第2の創業期」として、事業を拡大方針へと舵を切りました。会社が急拡大しており、若いメンバーやインターン生がどんどん入社しています。個人の成長は、勢いのある環境のなかでこそ加速されるものです。成長事業に参画できるチャンスです!
サイバーウェーブはコード1行1行に対してこだわりを持って、プロ意識をもったエンジニアを育てている、技術力に自信のあるシステム開発会社です。社内には、創業23年のノウハウの詰まった研修コンテンツや、安定したシステム開発をするための手順が整っています。実力のあるシステム開発会社だからこそ、経験を積みながら、実践的なシステム開発の技術も学ぶことができます。自信をもって主義主張ができる『飯が食える』エンジニアを目指していただきます。
エンジニアとしてしっかりと飯を食べていけるまでには、道のりは決して短くありません。長期で頑張り、エンジニアになるという強い思いがあれば、実戦的な開発経験と、周りの仲間とコミュニケーションしながら、しっかりと成長することができます。当社のノウハウを余すことなく活かし、技術力を大きく伸ばしていただきます。
ぜひ、エントリーをお待ちしております!
インターン採用
新卒・既卒・第二新卒採用





